Machine Learning (ML) system is an integrated computing environment composed of three fundamental components:
- Data that guides algorithmic behavior,
- Learning algorithms that extract patterns from this data, and
- Computing infrastructure that enables both the learning process (training) and the application of learned knowledge (inference or serving).
Together, these components form a dynamic ecosystem capable of making predictions, generating content, or taking autonomous actions based on learned patterns. Unlike traditional software systems, which rely on explicitly programmed logic, ML systems derive behavior from data and adapt over time through iterative learning processes. Understanding their architecture and interdependencies is essential to designing, operating, and maintaining reliable AI driven applications.
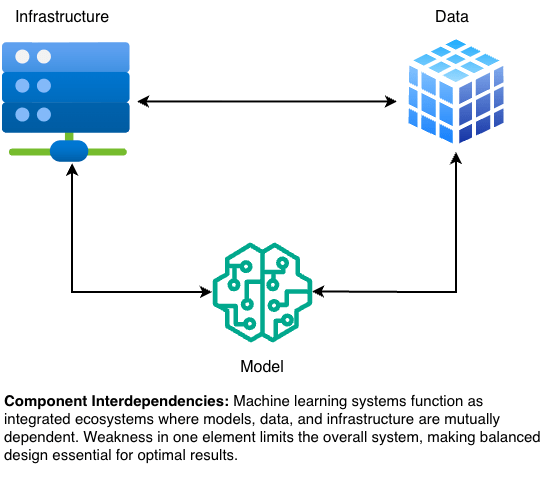
At the core of every ML system lies a triangular dependency among Models/Algorithms, Data, and Computing Infrastructure framework often referred to as the AI Triangle. Each of these components plays a distinct role while simultaneously shaping and constraining the others.
- Algorithms (Models) :- Mathematical frameworks and optimization methods that learn patterns or relationships within data to make predictions, classifications, or decisions.
- Data:- The lifeblood of ML systems comprising the processes, storage mechanisms, and management tools for collecting, cleaning, transforming, and serving information for both training and inference.
- Computing Infrastructure:- The hardware and software stack that powers the training, deployment, and operation of machine learning models at scale. This includes GPUs/TPUs, distributed computing clusters, data pipelines, and orchestration frameworks.
These three elements interact in a feedback loop. The model architecture determines computational requirements (such as GPU memory or parallel processing) and influences how much and what kind of data is necessary for effective learning. The volume, quality, and complexity of available data, in turn, constrain which model architectures can be effectively trained. Finally, the capabilities of the computing infrastructure its storage, networking, and compute capacity set practical limits on both the data scale and model complexity that can be supported.
In essence, no component operates in isolation. Algorithms require data and compute power to learn and large datasets need algorithms and infrastructure to extract value and infrastructure serves no purpose without the models and data it is designed to support. Effective system design thus requires balancing these interdependencies to achieve optimal performance, cost efficiency, and operational feasibility.
While both ML systems and traditional software rely on code and computation, their failure modes differ fundamentally. Traditional software follows deterministic logic when a bug occurs, the program crashes, error messages appear, and monitoring systems raise alerts. Failures are explicit and observable. Developers can pinpoint the root cause, fix the defect, and redeploy the corrected version.
Machine learning systems, however, exhibit implicit and often invisible degradation. ML system can continue to operate serving predictions and producing outputs while its underlying performance silently deteriorates. The algorithms keep running, and the infrastructure remains functional, yet the system’s predictive accuracy or contextual relevance declines. Because there are no explicit errors, standard software monitoring tools fail to detect the problem.
This distinction highlights why ML engineering requires a new class of observability and monitoring frameworks focused on data quality, model drift, and performance metrics rather than system uptime or error logs. ML systems demand continuous evaluation and retraining to maintain alignment with real-world conditions.
Autonomous vehicle’s perception system vividly illustrates this contrast. In traditional automotive software, the engine control unit either manages fuel injection correctly or raises diagnostic warnings. Failures are binary and immediately observable.
In contrast, an ML based perception model may experience gradual, unobserved performance decline. Suppose the model detects pedestrians with 95% accuracy during its initial deployment. Over time, as environmental conditions change seasonal lighting variations, new clothing styles, or weather patterns underrepresented in the training data the detection accuracy may drop to 85%. The vehicle continues to operate, and from the outside, the system appears stable. Yet, the subtle degradation introduces growing safety risks that remain invisible to conventional logging systems.
This silent failure mode where the system remains functional but less reliable is emblematic of ML engineering challenges. Only through systematic data auditing, reevaluation, and retraining can engineers detect and mitigate such degradation before it leads to unacceptable risk.
The phenomenon of silent degradation affects all three components of the AI Triangle simultaneously:
- Data Drift:- Over time, real world data distributions change. User behavior evolves, new edge cases emerge, and external factors such as seasonality or market shifts alter input patterns. The training data, once representative, becomes outdated.
- Algorithmic Staleness:- Models trained on past data continue to make predictions as if the world hasn’t changed. Their learned parameters no longer reflect current realities, leading to diminishing accuracy and relevance.
- Infrastructure Reinforcement:- The computing infrastructure, built for reliability and throughput, continues serving predictions flawlessly even as those predictions grow increasingly inaccurate. High uptime and low latency metrics mask the underlying problem, amplifying the scale of degraded decision-making.
Practical example for this behavior is e-commerce recommendation system. Initially achieving 85% accuracy in predicting user preferences, it may drop to 60% within months as customer tastes evolve and new products enter the catalog. Despite this decline, the system continues generating recommendations, users still see suggestions, and operational metrics report 100% uptime. However, the system’s business value silently erodes classic case of training serving skew, where the distribution of data during training diverges from that during real-world inference.
The insights of Richard Sutton, a pioneer in artificial intelligence and reinforcement learning, shed light on why these dynamics persist. Sutton’s research, including his co-authored textbook Reinforcement Learning: An Introduction, fundamentally shaped how machines learn from trial-and-error mirroring how humans acquire skills through experience.
In 2024, Sutton and Andrew Barto received the ACM Turing Award, computing’s highest honor, for their contributions to adaptive learning systems. Sutton’s influential essay, The Bitter Lesson, distills seven decades of AI research into one powerful observation that general methods that leverage large-scale computation consistently outperform approaches based on manually encoded human expertise.
This principle explains why modern ML systems, despite their sophistication, remain dependent on vast computational and data resources and why their fragility often stems from overreliance on statistical learning rather than explicit human understanding. Sutton’s perspective underscores the trade-off at the heart of the AI Triangle as systems grow more general and data-driven, they become more capable but also opaquer and more vulnerable to unnoticed performance decay.
Designing resilient machine learning systems requires acknowledging and managing these interdependencies and failure modes. Successful engineering practices includes
- Data Monitoring and Validation:- Continuously track input distributions, data quality, and label accuracy. Detect and respond to shifts early using statistical drift detection tools.
- Model Performance Tracking:- Evaluate model accuracy, precision, recall, and fairness metrics in production using live data. Implement automated retraining pipelines.
- Infrastructure Observability:- Extend system health monitoring to include model health metrics, not just uptime or latency.
- Feedback Loops:- Incorporate user feedback and edge case analysis to keep models aligned with evolving conditions.
- Ethical and Safety Considerations:- Recognize that silent degradation can have real-world consequences especially in healthcare, finance, and autonomous systems.
The future of ML engineering will depend less on building ever larger models and more on developing self-aware systems that detect and adapt to their own degradation concept sometimes referred to as self-healing AI infrastructure.
So now we understand as why OpenAI needs government support to fund and expand its operation and it’s due to bitter lesson.

Leave a comment